Нейронные сети стали ключевым элементом искусственного интеллекта, открывая возможности от распознавания лиц до медицинской диагностики. Эти математические модели, созданные по аналогии с работой мозга, совершенствуются благодаря гигантским массивам данных. Обучение сводится к поиску оптимальных параметров, снижающих погрешность прогнозов.
Функция потерь: карта успеха нейросетей
Главным ориентиром в обучении выступает функция потерь — индикатор ошибок нейросети. Чем ниже её значение, тем точнее предсказания. Её можно сравнить с трёхмерной картой: точки соответствуют параметрам модели, а «высота» отражает уровень потерь. Такой ландшафт помогает визуализировать путь к идеальным настройкам.
Путешествие по долинам минимумов
Обучение напоминает спуск в глубочайшую долину на сложном рельефе. Современные нейросети сталкиваются с миллионами локальных минимумов (небольших впадин) и редкими глобальными минимумами — идеальными точками. Поиск оптимального решения требует инновационных подходов, что подтверждают исследования МФТИ.
Геометрия успеха: плоские долины и матрица Гессе
Широкие «долины» ландшафта ассоциируются с моделями, которые эффективно работают на новых данных. Для анализа используют матрицу Гессе — инструмент, изучающий кривизну вокруг минимумов. Её спектр выявляет парадокс: большинство значений близки к нулю, но некоторые указывают на резкие изменения, что раскрыли учёные под руководством Андрея Грабового.
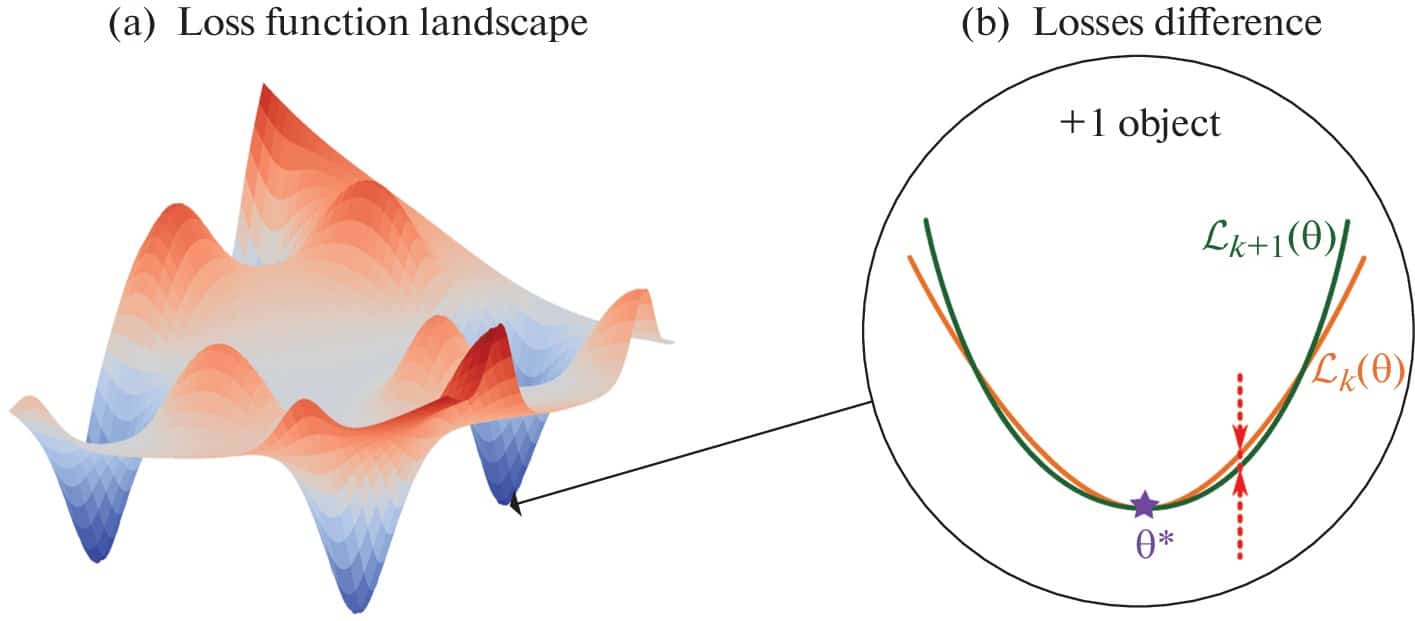
Динамика ландшафта: что происходит с новыми данными?
Долгое время оставалось загадкой, как добавление информации влияет на ландшафт. Стабилизируется ли он? Принимает ли чёткую форму? Команда МФТИ провела эксперименты: обучая сети на датасетах разного размера, они добавляли по одному элементу, фиксируя изменение потерь. Результаты показали закономерности, важные для будущего ИИ.
Методология: от пикселей к глубоким признакам
Исследователи тестировали как сырые пиксели изображений, так и признаки, извлечённые предобученными моделями. Многократное усреднение данных подтвердило: скорость снижения погрешности при расширении выборки имеет пределы. Это открытие задаёт вектор для оптимизации ресурсов в машинном обучении.
Стабилизация ландшафта потерь: теория и практика рука об руку
Исследования открыли удивительный факт: ландшафт функции потерь достигает стабильности по мере роста объёма данных! И теория, и эксперименты единодушно подтвердили: разница между средними потерями для выборок размером k и k+1 стремится к нулю при увеличении k. Более того, верхняя граница этой разницы снижается со скоростью ~1/k, демонстрируя сублинейную сходимость. Это словно природный закон, который направляет обучение нейросетей к гармонии.
Как параметры сети влияют на скорость стабилизации
Углубляясь в детали, учёные обнаружили интересные закономерности. Увеличение глубины сети (L) может замедлять сходимость из-за экспоненциальной зависимости в оценках. А вот влияние ширины слоёв (h) оказалось настоящим сюрпризом: вопреки первым предположениям, расширение сети способствует стабилизации! Этот парадокс объясняется способностью широких архитектур эффективнее адаптироваться к данным даже в простых задачах.
Эксперименты: триумф научного прогноза
Практика блестяще подтвердила теорию. На всех тестовых наборах и архитектурах наблюдалось снижение вариативности потерь с ростом выборки. Добавление слоёв действительно замедляло сходимость, а увеличение ширины — ускоряло, создавая идеальный баланс между сложностью модели и её adaptability. И что особенно важно: стабилизация происходила как с сырыми пикселями, так и с предобработанными признаками!
Прорыв в понимании динамики обучения
«Раньше мы рассматривали ландшафт потерь как застывший рельеф, — делится открытием Андрей Грабовой, доцент МФТИ. — Теперь видим его динамическую природу: он «успокаивается» по мере накопления данных. Это знание помогает определить момент, когда дополнительные данные перестают влиять на модель, открывая эру осознанного обучения нейросетей!»
Новый взгляд на эволюцию ландшафта
«Наше исследование впервые систематизировало, как размер выборки меняет геометрию потерь, — дополняет Никита Киселев, студент МФТИ. — Мы не просто доказали факт стабилизации, а вывели математические оценки скорости этого процесса. Это фундамент для создания более эффективных алгоритмов, учитывающих «поведение» ландшафта в реальном времени».
Эра разумной экономии ресурсов
Открытие революционизирует подход к обучению ИИ! Теперь можно разрабатывать системы, которые автоматически определяют достаточный объём данных. Как только ландшафт перестаёт меняться — обучение можно оптимизировать, экономя до 80% ресурсов на сбор данных и вычисления. Это не просто прогресс — это шаг к экологичному и осознанному искусственному интеллекту.
Перспективы оптимизации нейронных сетей
Глубокий анализ динамики ландшафта функции потерь открывает новые горизонты для создания передовых вычислительных решений. Это знание позволяет разрабатывать не только эффективные адаптивные алгоритмы, но и принципиально новые архитектуры, которые значительно ускорят обучение нейронных сетей.
Революция в машинном обучении
Понимание изменений в структуре функции потерь становится ключом к прорывам в области ИИ. Учёные уверены: такие исследования приведут к созданию интеллектуальных систем с беспрецедентной скоростью обработки данных и способностью к самооптимизации, что кардинально повысит эффективность и точность моделей будущего.
Источник: naked-science.ru





